

 民用天花板NAS能否一战?Z423旗舰版性能压榨,本地部署语音模型
民用天花板NAS能否一战?Z423旗舰版性能压榨,本地部署语音模型
亲爱的粉丝朋友们好啊!今天熊猫又来介绍好玩有趣的Docker项目了,喜欢的记得点个关注哦!
引言
2024一年NAS厂家都将重点放在了AI NAS上面,通过AI来进行更为精准的人脸识别、场景识别、文件检索以及视频识别等等,这一部分的AI模型最重要的并不是本地算力有多么厉害,毕竟简单识别人脸和文件并不需要太大的算力,难点在于模型的精准度以及AI的调教。极空间算是国内最早一批开始着手AI NAS的NAS厂商,在模型上也算是目前的第一梯队,比如首家支持AI字幕翻译的国产NAS,首家支持视频中人脸识别的NAS等等,且在自然语言搜索上极空间一直做得很不错,这一点熊猫也是试验过很多NAS的。
AI模型那么除了NAS厂商给到的模型,我们能不能自己选择,将模型部署到NAS中使用呢?常规来说,NAS的性能用来作为算力单位的确是有点难为它了,毕竟就算是早期的GPT3.5模型中也包含了1750亿个参数,想用NAS来计算还是多少有点乏力。不过还是有一些单一功能的小模型可以尝试在NAS上部署的,比如今天要介绍的fish-speech,一个基于VQ-GAN和Llama的文本转语音模型。(项目开源地址:https://github.com/fishaudio/fish-speech)
 项目页
项目页特性:
- 零样本 & 小样本 TTS:输入 10 到 30 秒的声音样本即可生成高质量的 TTS 输出。
- 多语言 & 跨语言支持:只需复制并粘贴多语言文本到输入框中,无需担心语言问题。目前支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
- 无音素依赖:模型具备强大的泛化能力,不依赖音素进行 TTS,能够处理任何文字表示的语言。
- 高准确率:在 5 分钟的英文文本上,达到了约 2% 的 CER(字符错误率)和 WER(词错误率)。
- 快速:通过 fish-tech 加速,在 Nvidia RTX 4060 笔记本上的实时因子约为 1:5,在 Nvidia RTX 4090 上约为 1:15。
- WebUI 推理:提供易于使用的基于 Gradio 的网页用户界面,兼容 Chrome、Firefox、Edge 等浏览器。
- GUI 推理:提供 PyQt6 图形界面,与 API 服务器无缝协作。支持 Linux、Windows 和 macOS。
易于部署:轻松设置推理服务器,原生支持 Linux、Windows 和 macOS,最大程度减少速度损失。
部署过程
这里还是要提前说明,虽说仅仅是支持10-30秒的语言模型,但其需要的算力还是比较大的,这里熊猫用的为极空间的Z423旗舰版,CPU为AMD锐龙7 5825U,也是目前消费级成品NAS天花板的配置,即便如此依然存在CPU拉满的情况,所以如果尝试部署,首先要先考虑考虑自己的NAS是否能承受得住。
 NAS性能
NAS性能部署前依然是检查好自己的NAS网络情况,该项目的镜像文件有4.29GB,在镜像下载之后还有4GB多的模型需要下载,所以如果网络不顺畅,那么前期的下载工作就需要浪费很多时间。这里推荐以下加速站,同时如果自己有代理,那么设置代理是最稳定的。
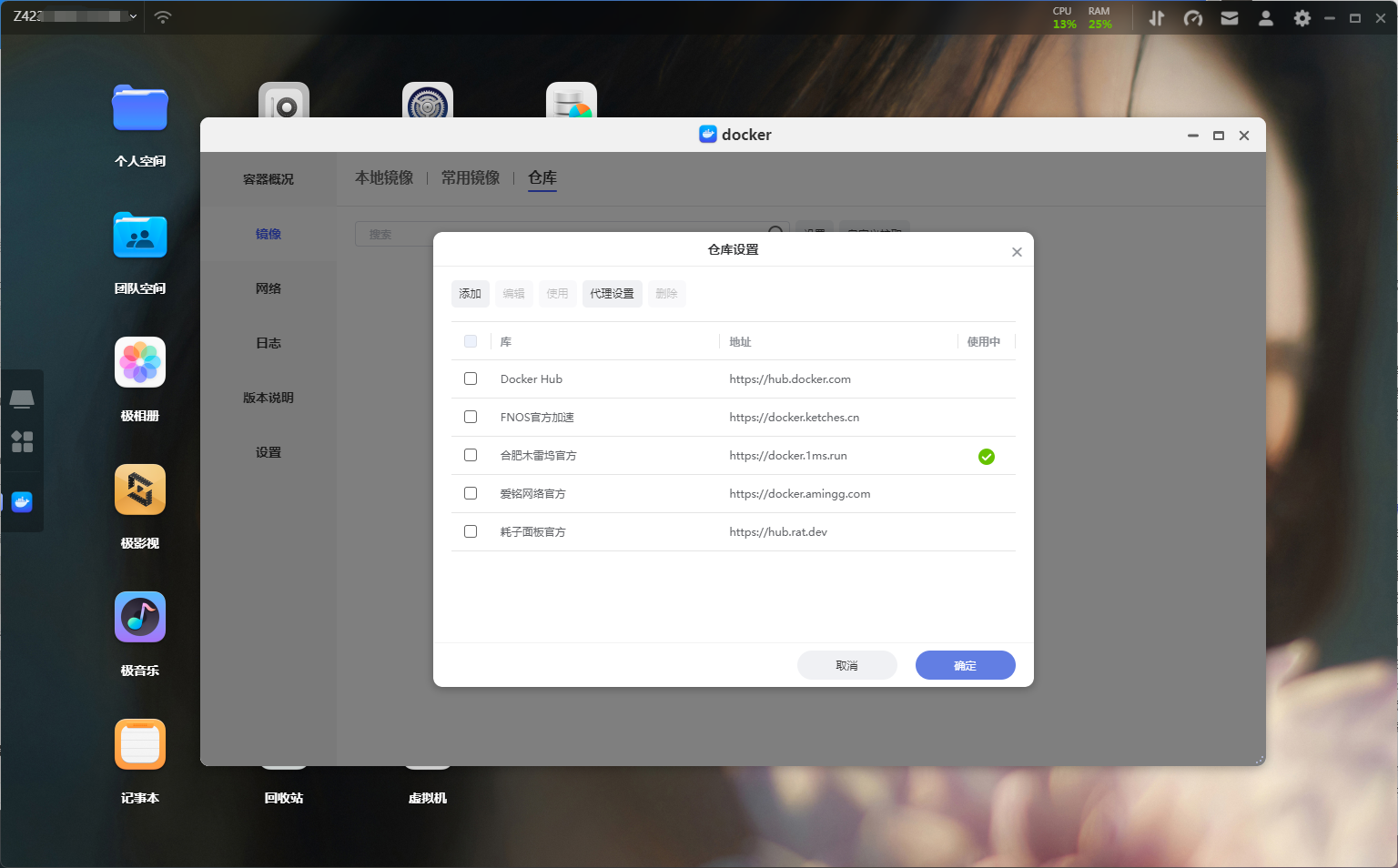 加速设置
加速设置准备好一切之后我们就可以开始拉取镜像了,打开极空间的镜像列表,切换到仓库选择自定义拉取,输入镜像名和标签:fishaudio/fish-speech:latest-dev,这里标签一定要记得输对。
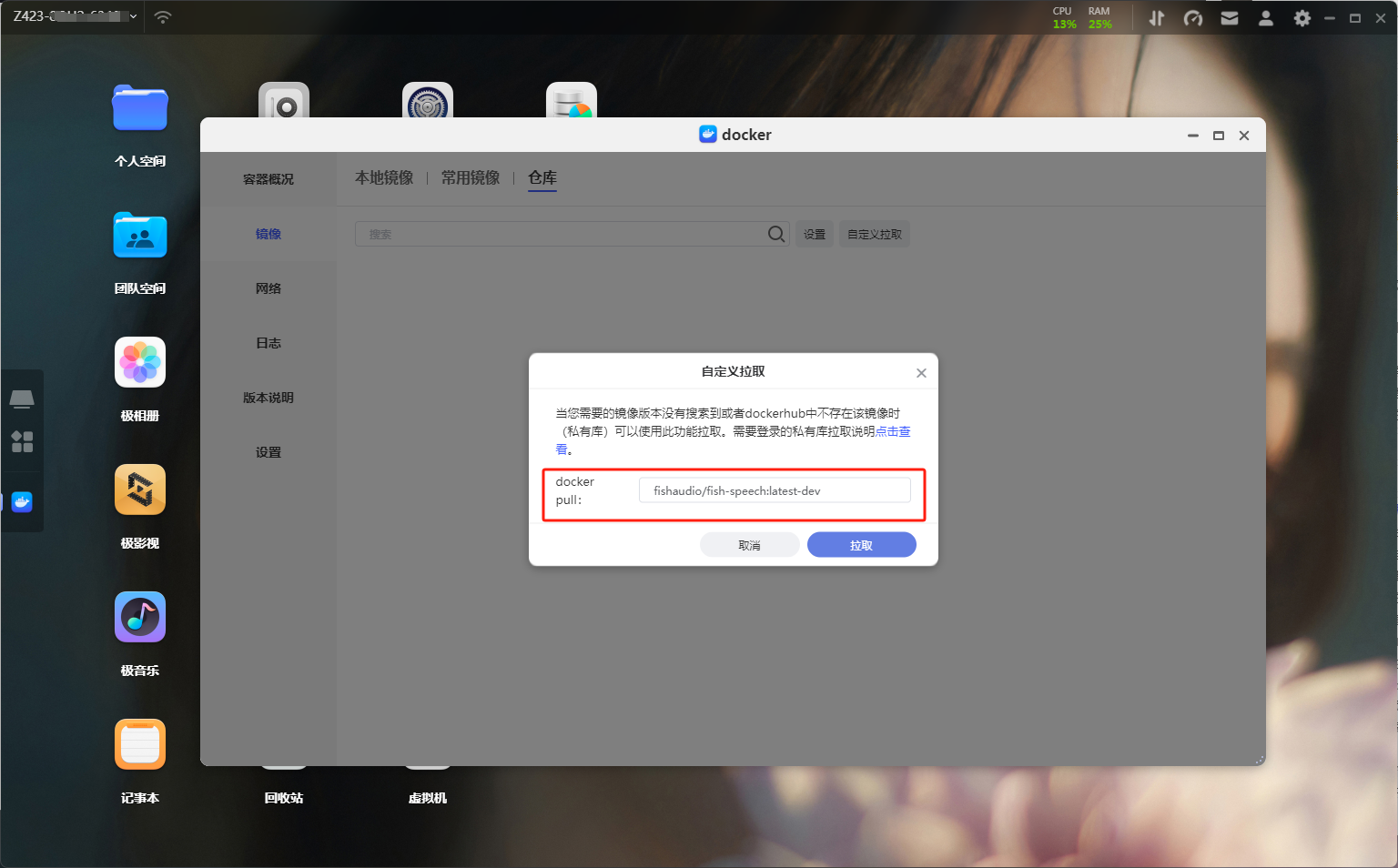 镜像拉取
镜像拉取初始镜像有4GB多,耐心等待一下。下载完毕之后在本地镜像中找到刚刚下载的镜像,双击创建容器,这里还是老规矩为了方便记忆给容器改一下名字。同时记得解除容器的性能限制,打开特权模式以及勾选上调用核心显卡功能。
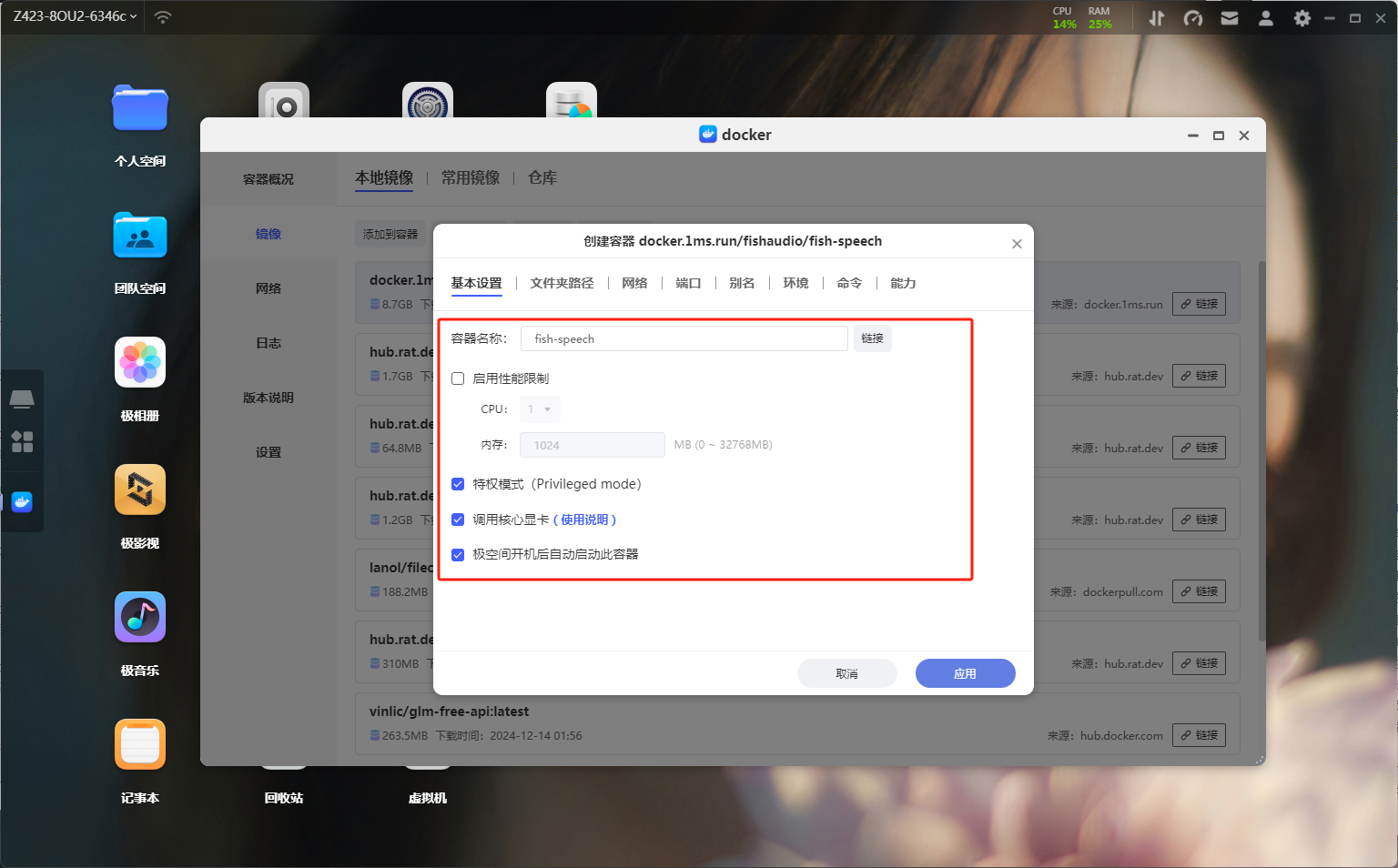 基础设置
基础设置来到端口界面,将容器端口7860映射到本地,本地端口随意,不冲突就行了。
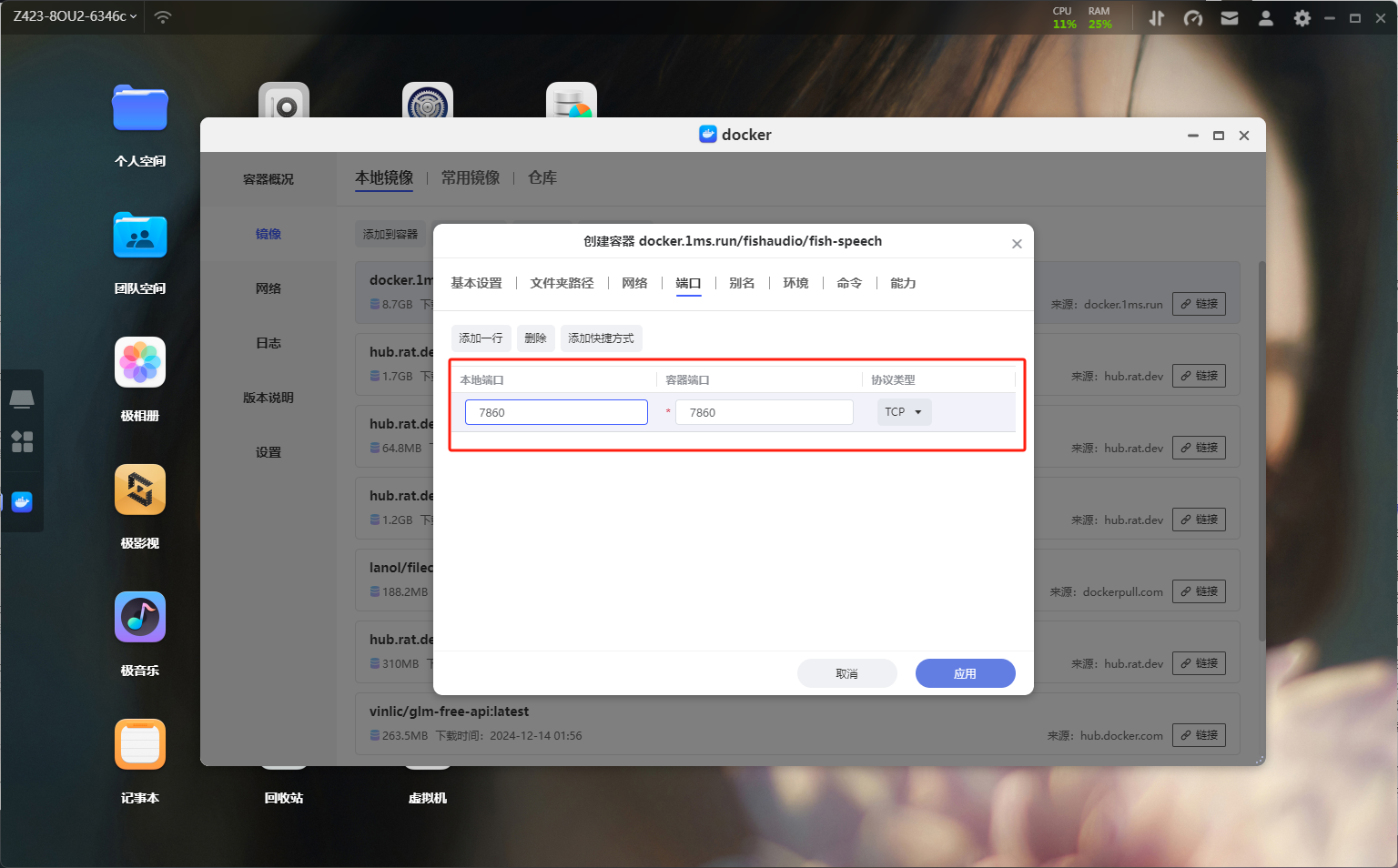 端口
端口最后点击应用这时候容器的初步设置就完成了。这时候你访问端口会发现无法访问,因为该项目默认是没有打开WEB UI的,所以我们需要使用命令开启。在容器概况中找到刚刚创建的容器,选择SSH功能,命令选择/bin/bash,用户为root。
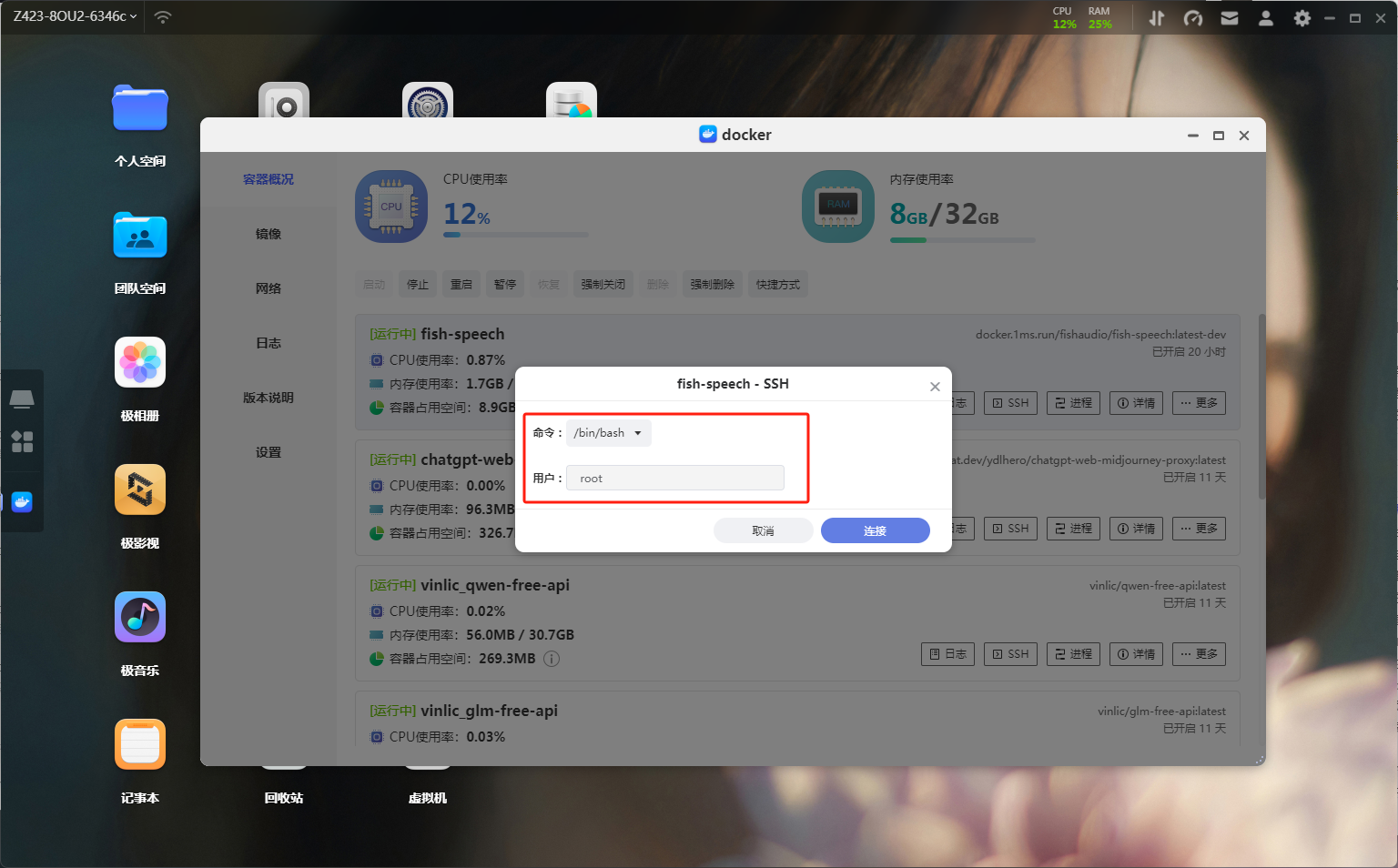 SSH设置
SSH设置在容器的终端界面输入export GRADIO_SERVER_NAME="0.0.0.0",从而让外部可以访问 docker 内的 gradio 服务。 接着在 docker 容器内的终端,输入python tools/run_webui.py即可开启 WebUI 服务。
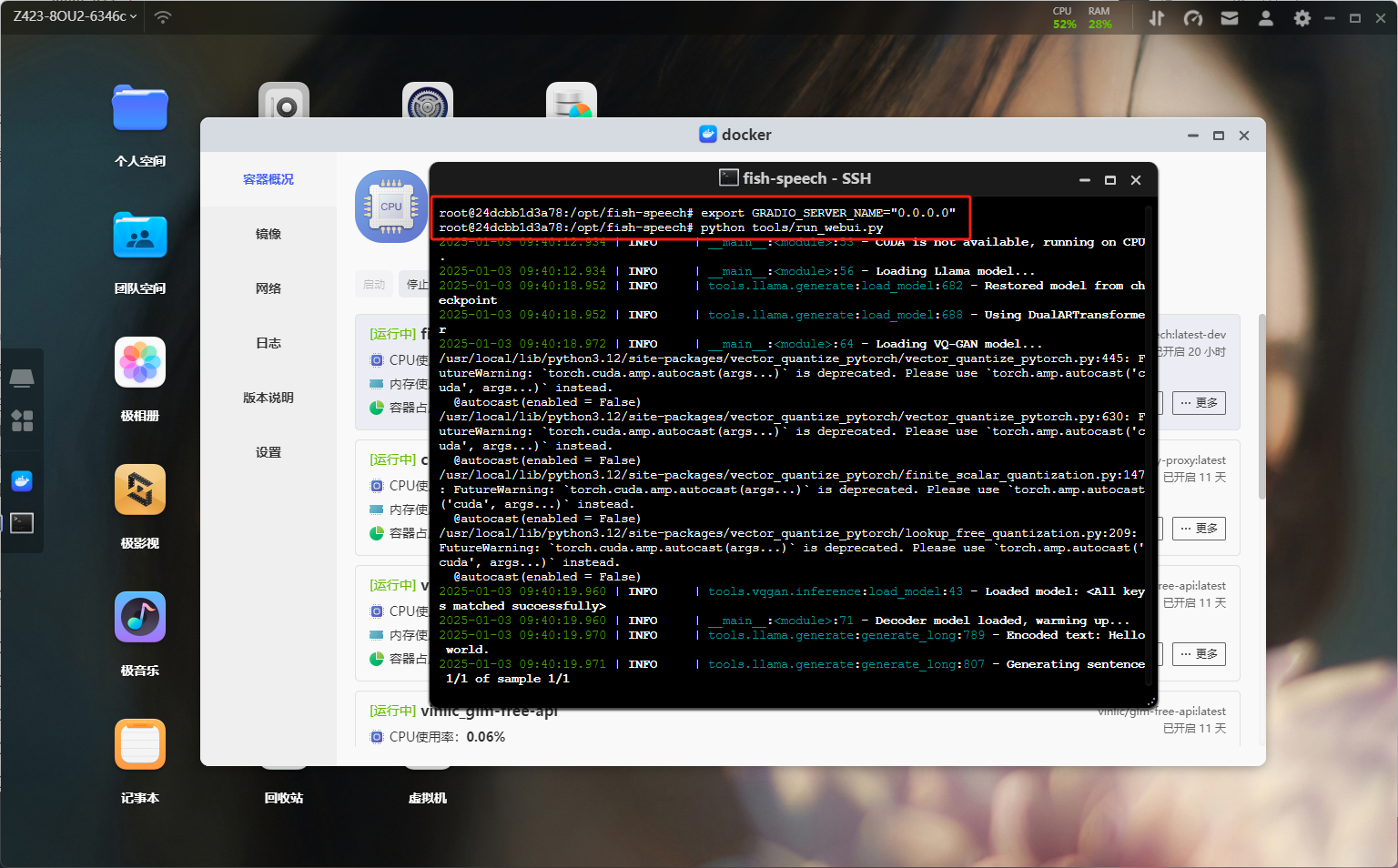 命令执行
命令执行这时候我们还需要下载需要的两个模型,分别是vqgan和llama模型。同样的还是在终端输入命令即可:HF_ENDPOINT=https://hf-mirror.com huggingface-cli download fishaudio/fish-speech-1.5 --local-dir checkpoints/fish-speech-1.5。(熊猫这里因为已经下载过了,所以执行之后直接显示)
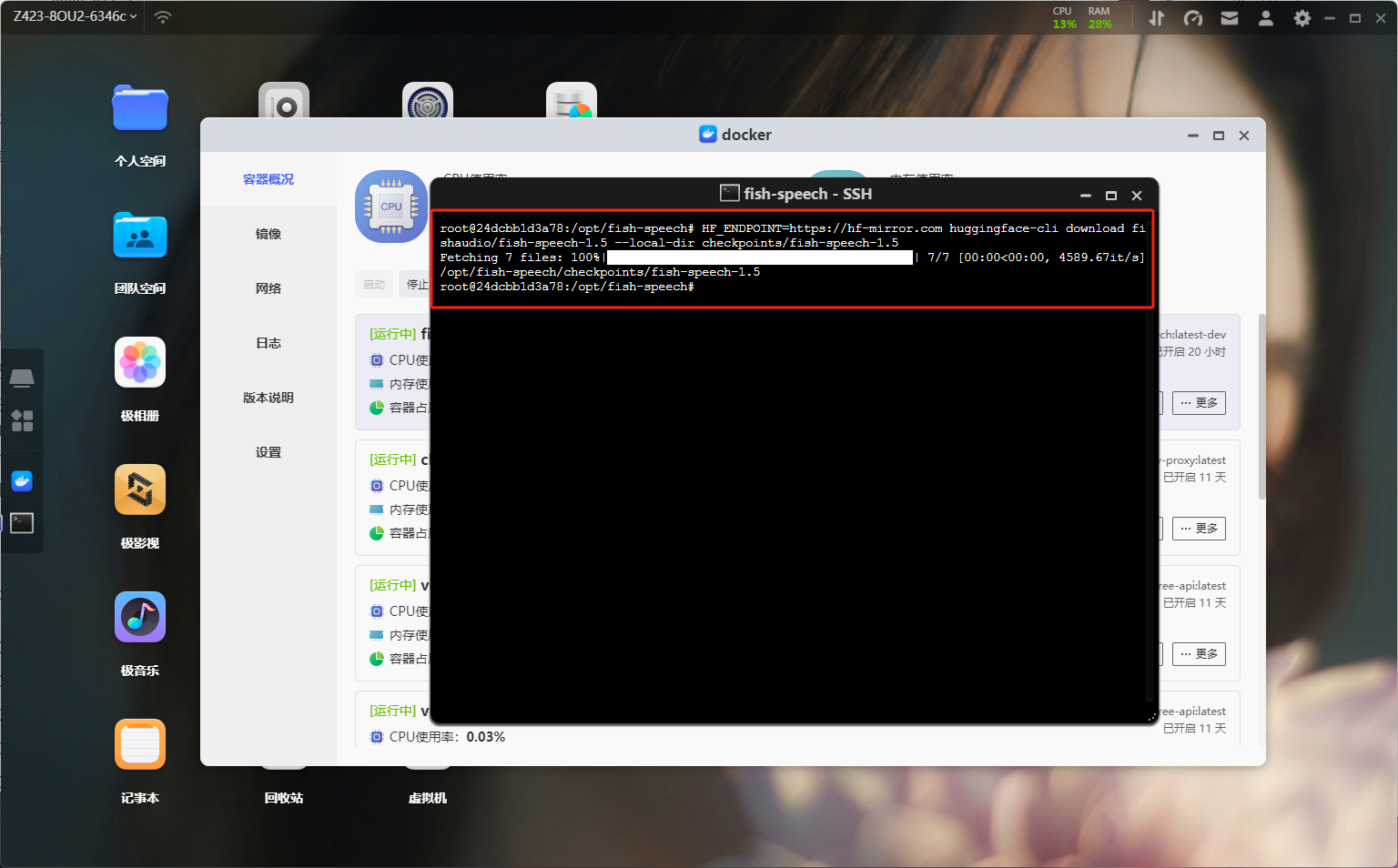 模型下载
模型下载项目使用
上述所有步骤完成之后,这时候就算是在极空间上成功的搭建好了本地模型了。这时候浏览器输入http://极空间IP:7860就能访问项目的WEB UI界面了,默认是英文界面,切不支持中文,不过咱们有万能的网页翻译。
 UI界面
UI界面如何使用呢?通过网页翻译可以得知,在左侧下方有两个文本输入框,上方输入文本下方则会显示实时转换后的文本,这个文本内容是一致的,只不过下方的文本是用于模型方便识别做了编码格式规范。
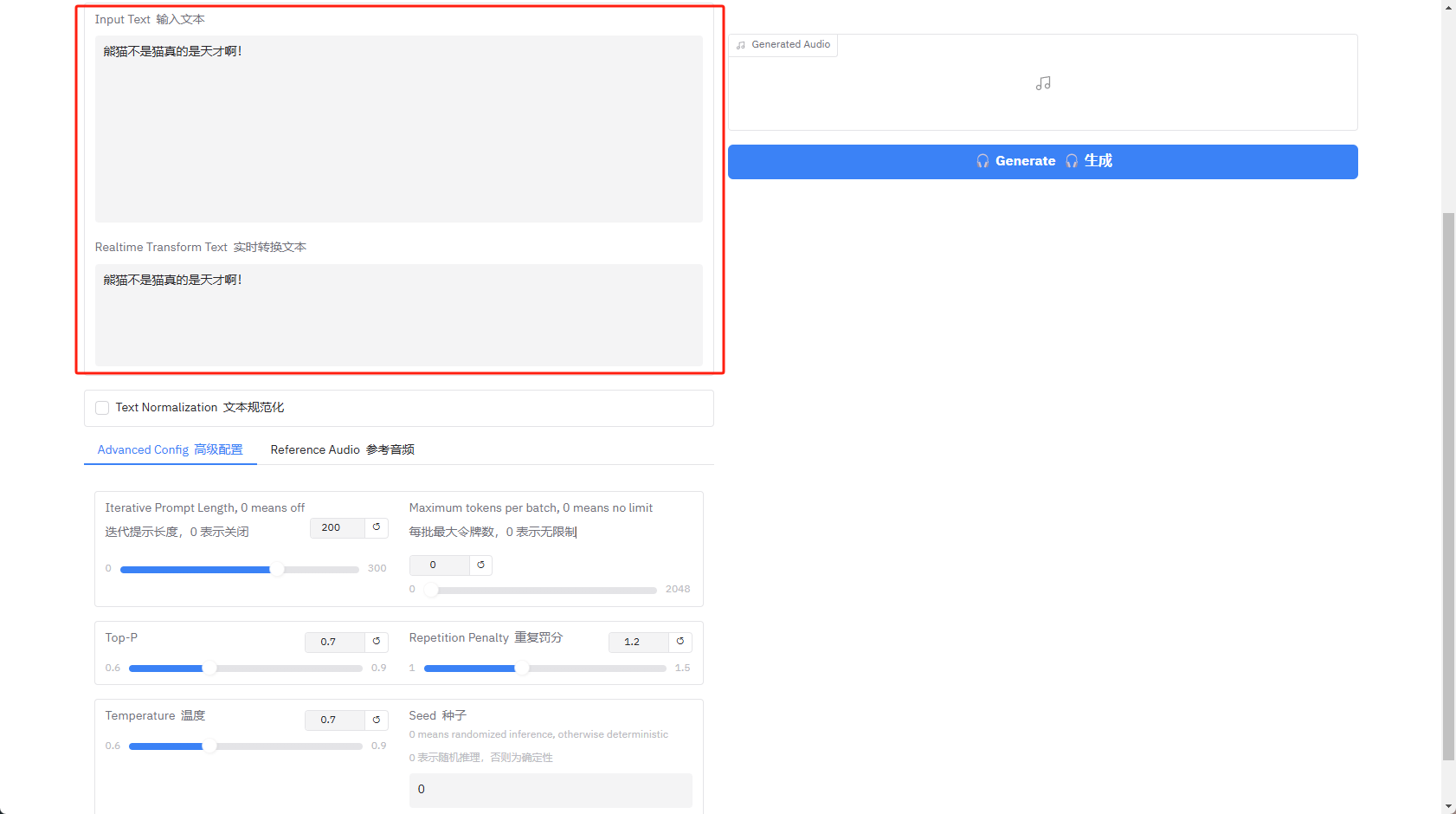 文本输入
文本输入再看下方的高级配置,第一排的迭代提示长度代表和模型的契合度,你可以理解为AI绘图中的参考性,后面的什么令牌、Top-P这些熊猫其实也没看懂,感兴趣的可以多次尝试调试试试。
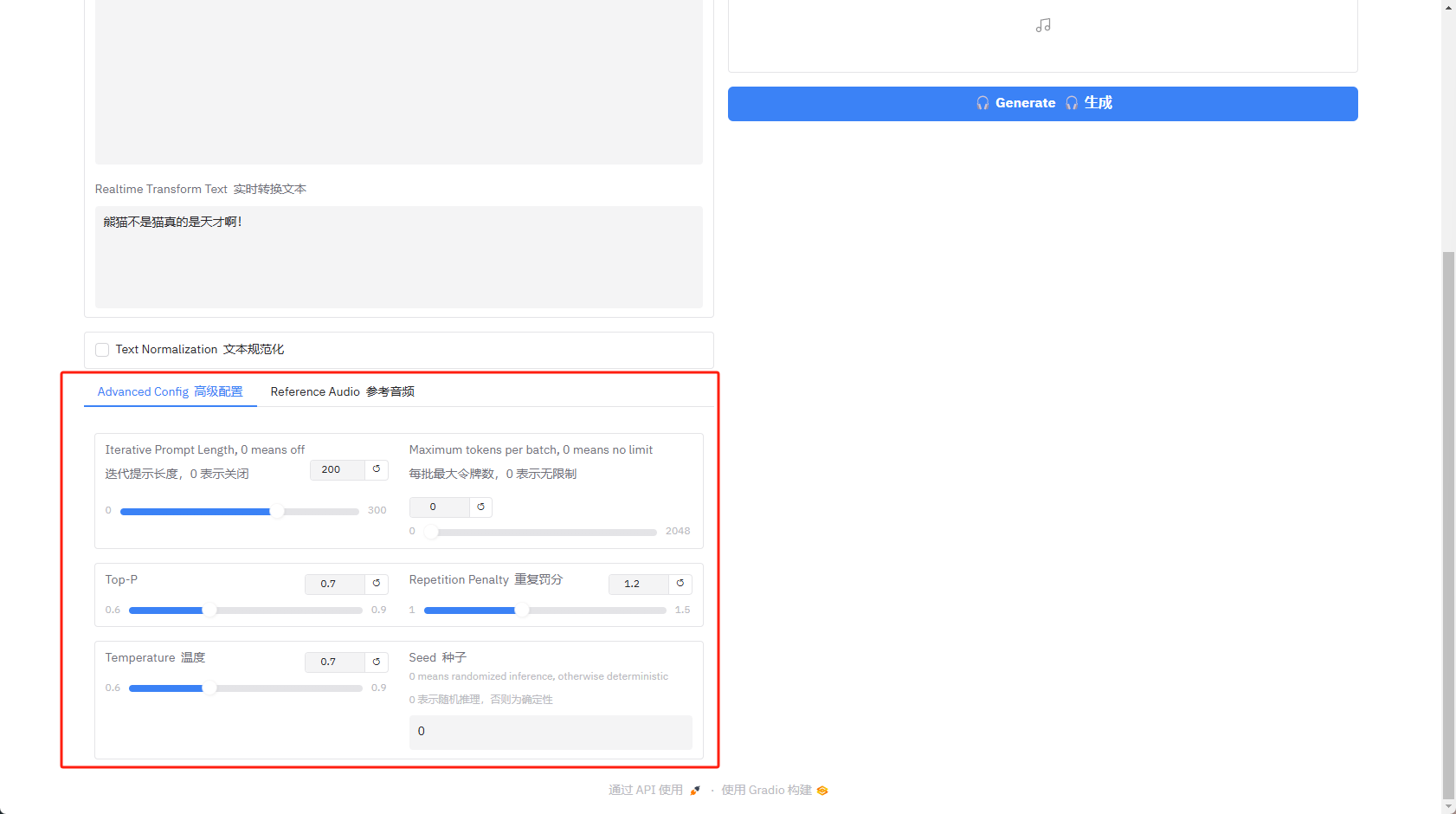 高级配置
高级配置在高级配置旁边还有参考音频的设置,例如我想要我输入的文字用什么音色发出,例如我可以录制一段我老婆的声音,随后生成的音频便为我老婆的语调和音色。这里熊猫下载了一段原神中纳西妲角色的配音,用来作为参考值。
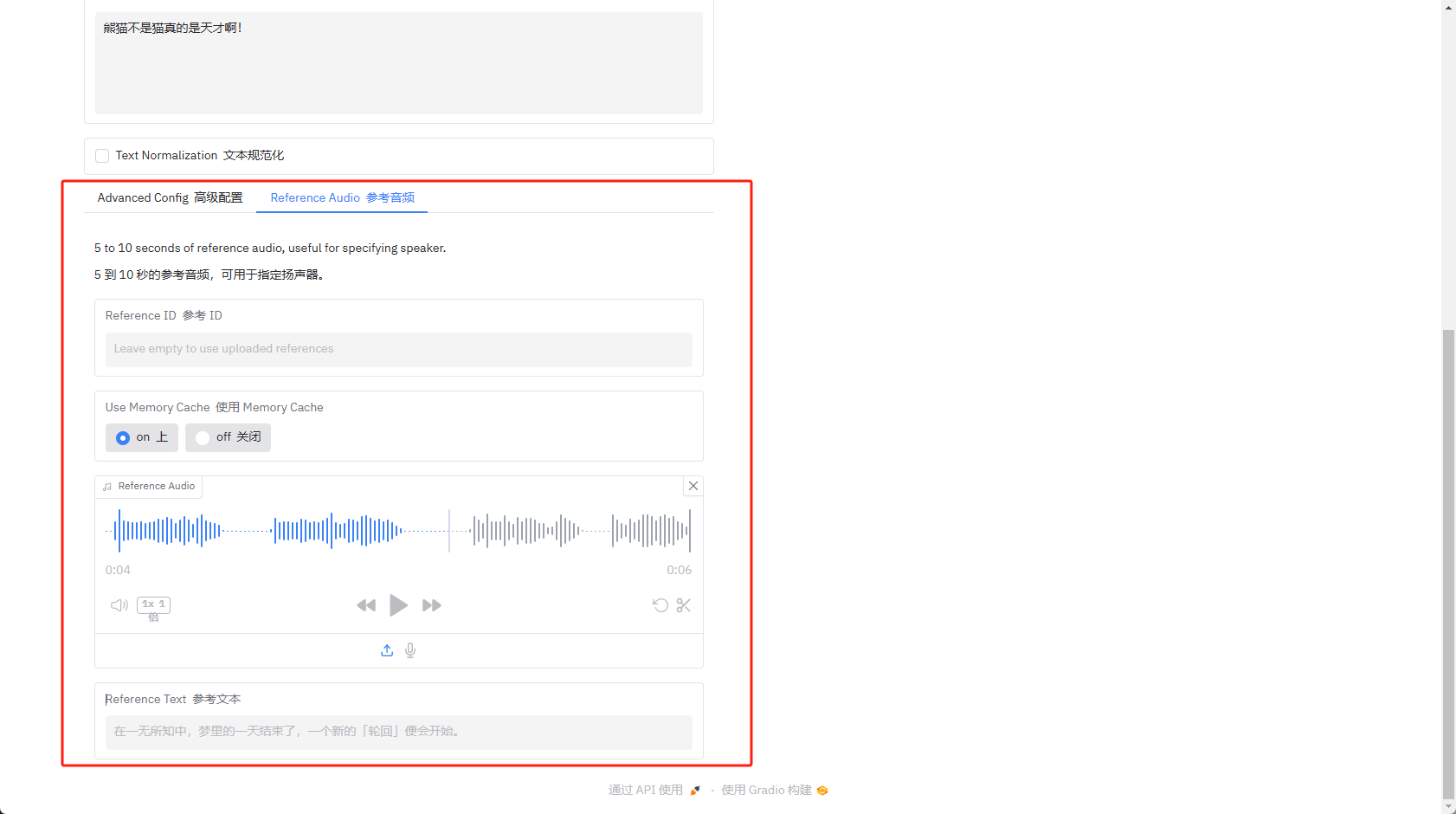 参考音频
参考音频最后点击右边的Generate生成音频即可,这个速度根据CPU性能而定,熊猫这里这句话11个汉字,同时加了参考音频的情况下,用Z423旗舰版生成花费用时280多秒,各位可以用Z423旗舰版的CPU性能作为参考,也能算出自己的NAS生成一段音频需要时长。
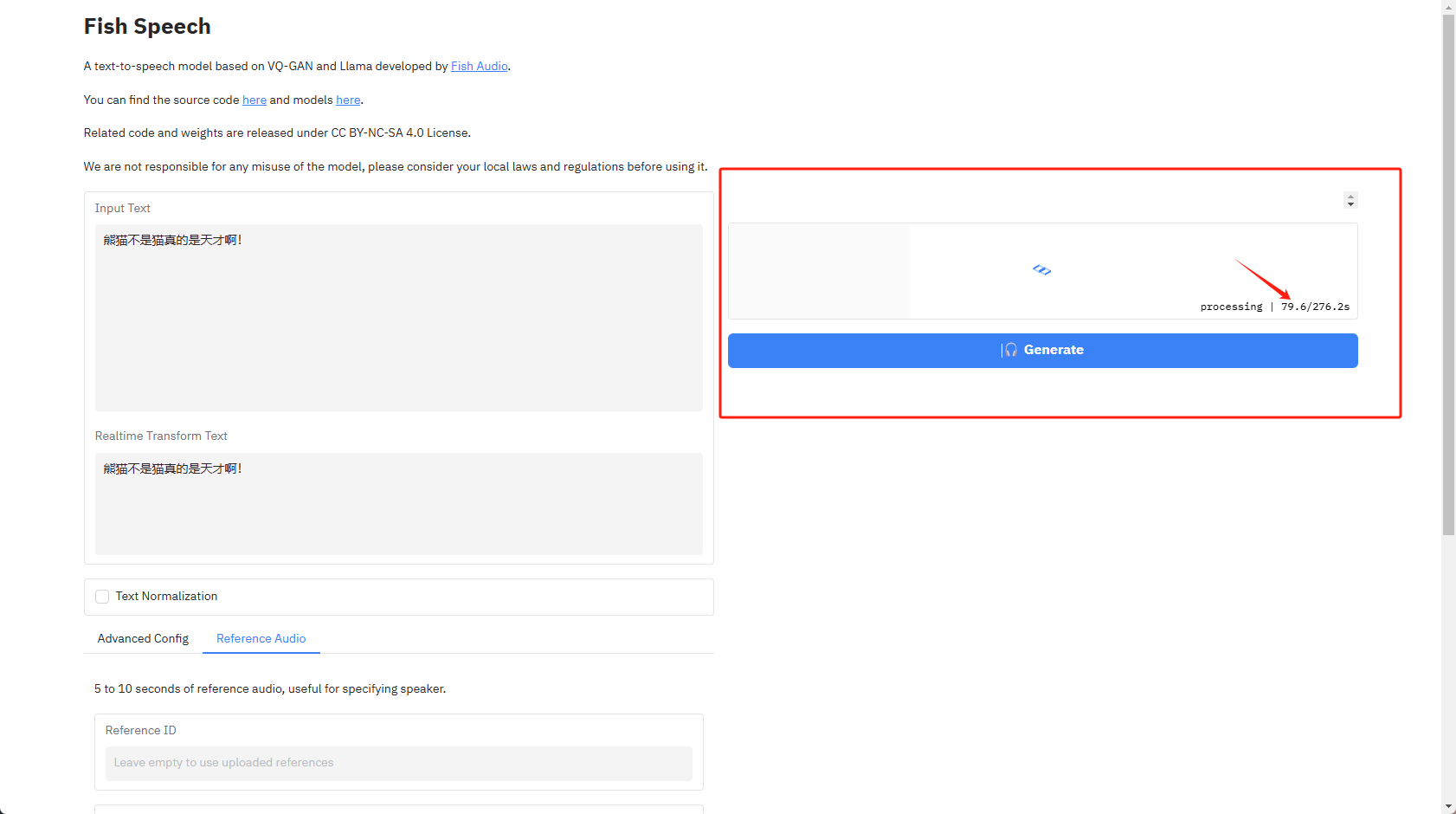 语音生成
语音生成生成过程中CPU会占用比较高,NAS的温度会随之上升,这是正常情况,不要惊慌,生成过程内存消耗不会怎么增加,毕竟算力对于内存的需求基本没有。(截图为生成结束之后5秒左右的截图,Z423的散热还是蛮不错的)
 性能消耗
性能消耗音频生成结束之后就能直接试听了,同时支持配速调整,点击右上角可以直接将音频下载到本地,个人还是比较满意这个结果的,蛮有意思的。
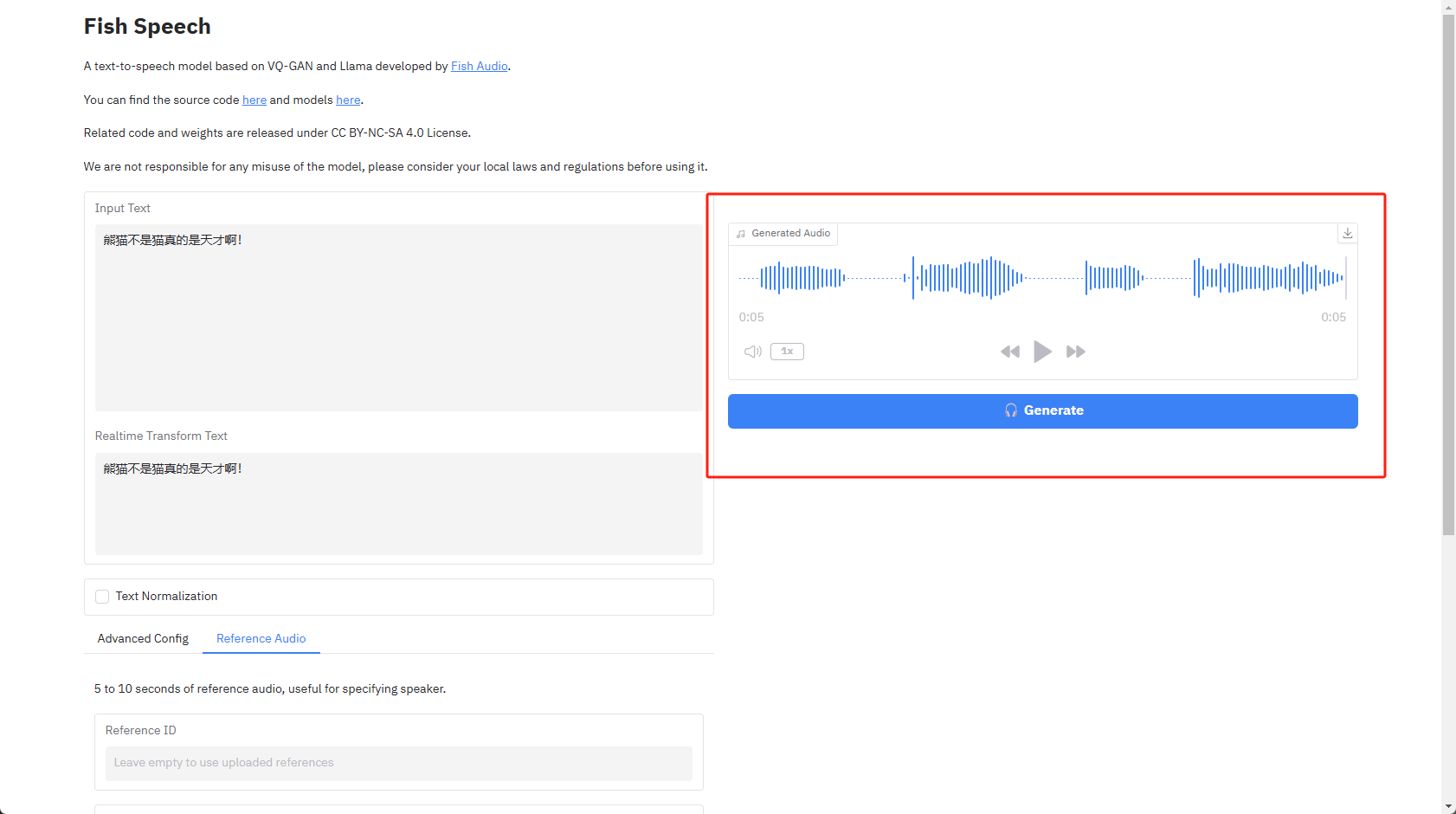 生成结果
生成结果总结
对于没玩过本地模型的,还是可以尝试下的,但如果你的NAS性能一般,那么可能这个生成速度就非常慢了。这里还是建议大家用性能高一点的NAS来尝试,这样体验感会高一些,快过年了,给自己买一台Z423旗舰版犒劳下自己吧!!!
以上便是本期的全部内容了,如果你觉得还算有趣或者对你有所帮助,不妨点赞收藏,最后也希望能得到你的关注,咱们下期见! 三连
三连



