

 基于大语言模型知识问答应用落地实践 – 知识库构建(上)
基于大语言模型知识问答应用落地实践 – 知识库构建(上)
背景介绍
随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)+知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通用大语言模型的一些短板,解决通用大语言模型在专业领域回答缺乏依据、存在幻觉等问题。其基本思路是把私域知识文档进行切片,然后向量化后续通过向量检索进行召回,再作为上下文输入到大语言模型进行归纳总结。 亚马逊云科技免费体验链接
在这个技术方向的具体实践中,知识库可以采取基于倒排和基于向量的两种索引方式进行构建,它对于知识问答流程中的知识召回这步起关键作用,和普通的文档索引或日志索引不同,知识的向量化需要借助深度模型的语义化能力、存在文档切分、向量模型部署&推理等额外步骤。知识向量化建库过程中,不仅仅需要考虑原始的文档量级,还需要考虑切分粒度,向量维度等因素,最终被向量数据库索引的知识条数可能达到一个非常大的量级,可能由以下两方面的原因引起:
各个行业的既有文档量很高,如金融、医药、法律领域等,新增量也很大。
为了召回效果的追求,对文档的切分常常会采用按句或者按段进行多粒度的冗余存贮。
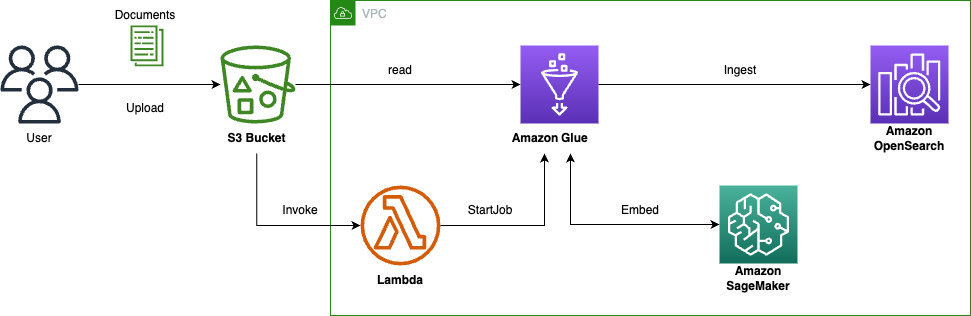
亚马逊云科技 这些细节对知识向量数据库的写入和查询性能带来一定的挑战,为了优化向量化知识库的构建和管理,本文基于亚马逊云科技的服务,构建了如下图的知识库构建流程:
通过 S3 Bucket 的 Handler 实时触发 Amazon Lambda 启动对应知识文件入库的 Amazon Glue job;
Glue Job 中会进行文档解析和拆分,并调用 Amazon Sagemaker 的 Embedding 模型进行向量化;
通过 Bulk 方式注入到 Amazon OpenSearch 中去。
phpHNlyry65b0ef351566e.jpg并对整个流程中涉及的多个方面,包括如何进行知识向量化、向量数据库调优总结了一些最佳实践和心得。
知识向量化
2.1 文档拆分
知识向量化的前置步骤是进行知识的拆分,语义完整性的保持是最重要的考量。分两个方面展开讨论。该如何选用以下两个关注点分别总结了一些经验:
a. 拆分片段的方法
关于这部分的工作,Langchain 作为一种流行的大语言模型集成框架,提供了非常多的 Document Loader 和 Text Spiltters,其中的一些实现具有借鉴意义,但也有不少实现效果是重复的。
目前使用较多的基础方式是采用 Langchain 中的 RecursiveCharacterTextSplitter,属于是 Langchain 的默认拆分器。它采用这个多级分隔字符列表 – [“\n\n”, “\n”, ” “, “”] 来进行拆分,默认先按照段落做拆分,如果拆分结果的 chunk_size 超出,再继续利用下一级分隔字符继续拆分,直到满足 chunk_size 的要求。
但这种做法相对来说还是比较粗糙,还是可能会造成一些关键内容会被拆开。对于一些其他的文档格式可以有一些更细致的做法。
FAQ 文件,必须按照一问一答粒度拆分,后续向量化的输入可以仅仅使用问题,也可以使用问题+答案(本系列 blog 的后续文章会进一步讨论)
Markdown 文件,”#”是用于标识标题的特殊字符,可以采用 MarkdownHeaderTextSplitter 作为分割器,它能更好的保证内容和标题对应的被提取出来。
PDF 文件,会包含更丰富的格式信息。Langchain 里面提供了非常多的 Loader,但 Langchain 中的 PDFMinerPDFasHTMLLoader 的切分效果上会更好,它把 PDF 转换成 HTML,通过 HTML 的 < div > 块进行切分,这种方式能保留每个块的字号信息,从而可以推导出每块内容的隶属关系,把一个段落的标题和上一级父标题关联上,使得信息更加完整。类似下面这种效果。
 phpPFUkMf65b0ef49a3bf8.jpg
phpPFUkMf65b0ef49a3bf8.jpgb. 模型对片段长度的支持
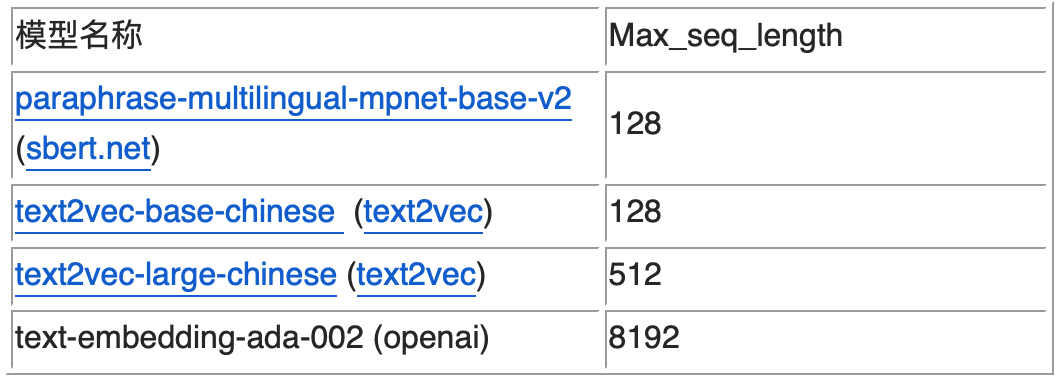
由于拆分的片段后续需要通过向量化模型进行推理,所以必须考虑向量化模型的 Max_seq_length 的限制,超出这个限制可能会导致出现截断,导致语义不完整。从支持的 Max_seq_length 来划分,目前主要有两类 Embedding 模型,如下表所示(这四个是有过实践经验的模型)。
 phpumi64065b0ef54187c8.jpg
phpumi64065b0ef54187c8.jpg这里的 Max_seq_length 是指 Token 数,和字符数并不等价。依据之前的测试经验,前三个模型一个 token 约为 1.5 个汉字字符左右。而对于大语言模型,如 chatglm,一个 token 一般为 2 个字符左右。如果在切分时不方便计算 token 数,也可以简单按照这个比例来简单换算,保证不出现截断的情况。
前三个模型属于基于 Bert 的 Embedding 模型,OpenAI 的 text-embedding-ada-002 模型是基于 GPT3 的模型。前者适合句或者短段落的向量化,后者 OpenAI 的 SAAS 化接口,适合长文本的向量化,但不能私有化部署。
可以根据召回效果进行验证选择。从目前的实践经验上看 text-embedding-ada-002 对于中文的相似性打分排序性可以,但区分度不够(集中 0.7 左右),不太利于直接通过阈值判断是否有相似知识召回。
另外,对于长度限制的问题也有另外一种改善方法,可以对拆分的片段进行编号,相邻的片段编号也临近,当召回其中一个片段时,可以通过向量数据库的 range search 把附近的片段也召回回来,也能保证召回内容的语意完整性。
2.2 向量化模型选择
上节提到四个模型只是提到了模型对于文本长度的支持差异,效果方面目前并没有非常权威的结论。可以通过 leaderboard 来了解各个模型的性能,榜上的大多数的模型的评测还是基于公开数据集的 benchmark,对于真实生产中的场景 benchmark 结论是否成立还需要 case by case 地来看。但原则上有以下几方面的经验可以分享:
经过垂直领域 Finetune 的模型比原始向量模型有明显优势;
目前的向量化模型分为两类,对称和非对称。未进行微调的情况下,对于 FAQ 建议走对称召回,也就是 Query 到 Question 的召回。对于文档片段知识,建议使用非对称召回模型,也就是 Query 到 Answer(文档片段)的召回;
没有效果上的明显的差异的情况下,尽量选择向量维度短的模型,高维向量(如 openai 的 text-embedding-ada-002)会给向量数据库造成检索性能和成本两方面的压力。
更多的内容会在本系列的召回优化部分进行深入讨论。
2.3 向量化并行
真实的业务场景中,文档的规模在百到百万这个数量级之间。按照冗余的多级召回方式,对应的知识条目最高可能达到亿的规模。由于整个离线计算的规模很大,所以必须并发进行,否则无法满足知识新增和向量检索效果迭代的要求。步骤上主要分为以下三个计算阶段。
 phpb5Nmm065b0ef6a2c42b.jpg
phpb5Nmm065b0ef6a2c42b.jpg文档切分并行
计算的并发粒度是文件级别的,处理的文件格式也是多样的,如 TXT 纯文本、Markdown、PDF 等,其对应的切分逻辑也有差异。而使用 Spark 这种大数据框架来并行处理过重,并不合适。使用多核实例进行多进程并发处理则过于原始,任务的观测追踪上不太方便。所以可以选用 Amazon Glue 的 Python shell 引擎进行处理。主要有如下好处:
方便的按照文件粒度进行并发,并发度简单可控。具有重试、超时等机制,方便任务的追踪和观察,日志直接对接到 Amazon CloudWatch;
方便的构建运行依赖包,通过参数–additional-python-modules 指定即可,同时 Glue Python 的运行环境中已经自带了 opensearch_py 等依赖。
可参考如下代码:
glue = boto3.client('glue')def start_job(glue_client, job_name, bucket, prefix):response = glue.start_job_run(JobName=job_name,Arguments={'--additional-python-modules':'pdfminer.six==20221105,gremlinpython==3.6.3,langchain==0.0.162,beautifulsoup4==4.12.2','--doc_dir': f'{prefix}','--REGION':'us-west-2','--doc_bucket': f'{bucket}','--AOS_ENDPOINT':'vpc-aos-endpoint','--EMB_MODEL_ENDPOINT':'emb-model-endpoint'})returnresponse['JobRunId']
注意:Amazon Glue 每个账户默认的最大并发运行的 Job 数为 200 个,如果需要更大的并发数,需要申请提高对应的 Service Quota,可以通过后台或联系客户经理。
向量化推理并行
由于切分的段落和句子相对于文档数量也膨胀了很多倍,向量模型的推理吞吐能力决定了整个流程的吞吐能力。这里采用 SageMaker Endpoint 来部署向量化模型,一般来说为了提供模型的吞吐能力,可以采用 GPU 实例推理,以及多节点 Endpoint/Endpoint 弹性伸缩能力,Server-Side/Client-Side Batch 推理能力这些都是一些有效措施。具体到离线向量知识库构建这个场景,可以采用如下几种策略:
GPU 实例部署
向量化模型 CPU 实例是可以推理的。但离线场景下,推理并发度高,GPU 相对于 CPU 可以达到 20 倍左右的吞吐量提升。所以离线场景可以采用 GPU 推理,在线场景 CPU 推理的策略。
多节点 Endpoint
对于临时的大并发向量生成,通过部署多节点 Endpoint 进行处理,处理完毕后可以关闭(注意:离线生成的请求量是突然增加的,Auto Scaling 冷启动时间 5-6 分钟,会导致前期的请求出现错误)
利用 Client-Side Batch 推理
离线推理时,Client-side batch 构造十分容易。无需开启 Server-side Batch 推理,一般来说 Sever-side batch 都会有个等待时间,如 50ms 或 100ms,对于推理延迟比较高的大语言模型比较有效,对于向量化推理则不太适用。可以参考如下代码:
importhashlibimportitertoolsimportreBATCH_SIZE =30paragraph_content='sentence1。sentence2。sentence3。sentence4。sentence5。sentence6.'def sentence_generator(paragraph_content):sentences = re.split('[。??.!!]', paragraph_content)forsent in sentences:yield sentdef batch_generator(generator, batch_size):whileTrue:batch =list(itertools.islice(generator, batch_size))ifnotbatch:breakyield batchg = sentence_generator(paragraph_content)sentence_batches = batch_generator(g, batch_size=BATCH_SIZE)# iterate batch to inferforidx, batch in enumerate(sentence_batches):# client-side batch inferenceembeddings = get_embedding(smr_client, batch, endpoint_name)forsent_id, sent in enumerate(batch):document = {"publish_date": publish_date,"idx":idx,"doc": sent,"doc_type":"Sentence","content": paragraph_content,"doc_title": header,"doc_category":"","embedding": embeddings[sent_id]}yield {"_index": index_name,"_source": document,"_id": hashlib.md5(str(document).encode('utf-8')).hexdigest()}
OpenSearch 批量注入
Amazon OpenSearch 的写入操作,在实现上可以通过 bulk 批量进行,比单条写入有很大优势。参考如下代码:
from opensearchpyimportOpenSearch, RequestsHttpConnection,helperscredentials = boto3.Session().get_credentials()auth = AWSV4SignerAuth(credentials, region)client = OpenSearch(hosts = [{'host': aos_endpoint,'port':443}],http_auth = auth,use_ssl = True,verify_certs = True,connection_class = RequestsHttpConnection)gen_aos_record_func = Noneifcontent_type =="faq":gen_aos_record_func = iterate_QA(file_content, smr_client, index_name, EMB_MODEL_ENDPOINT)elif content_type in ['txt','pdf','json']:gen_aos_record_func = iterate_paragraph(file_content, smr_client, index_name, EMB_MODEL_ENDPOINT)else:raise RuntimeError('No Such Content type supported')response = helpers.bulk(client, gen_aos_record_func)returnresponse
向量数据库优化
向量数据库选择哪种近似搜索算法,选择合适的集群规模以及集群设置调优对于知识库的读写性能也十分关键,主要需要考虑以下几个方面:
3.1 算法选择
在 OpenSearch 里,提供了两种 k-NN 的算法:HNSW (Hierarchical Navigable Small World) 和 IVF (Inverted File) 。
在选择 k-NN 搜索算法时,需要考虑多个因素。如果内存不是限制因素,建议优先考虑使用 HNSW 算法,因为 HNSW 算法可以同时保证 latency 和 recall。如果内存使用量需要控制,可以考虑使用 IVF 算法,它可以在保持类似 HNSW 的查询速度和质量的同时,减少内存使用量。但是,如果内存是较大的限制因素,可以考虑为 HNSW 或 IVF 算法添加 PQ 编码,以进一步减少内存使用量。需要注意的是,添加 PQ 编码可能会降低准确率。因此,在选择算法和优化方法时,需要综合考虑多个因素,以满足具体的应用需求。
3.2 集群规模预估
选定了算法后,我们就可以根据公式,计算所需的内存进而推导出 k-NN 集群大小, 以 HNSW 算法为例:
占用内存 = 1.1 (4d + 8m) num_vectors * (number_of_replicas + 1)
其中 d:vector 的维度,比如 768;m:控制层每个节点的连接数;num_vectors:索引中的向量 doc 数
3.3 批量注入优化
在向知识向量库中注入大量数据时,我们需要关注一些关键的性能优化,以下是一些主要的优化策略:
Disable refresh interval
在首次摄入大量数据时,为了避免生成较多的小型 segment,我们可以增大刷新的间隔,或者直接在摄入阶段关闭 refresh_interval(设置成 -1)。等到数据加载结束后,再重新启用 refresh_interval。
PUT /my_index/_settings{"index": {"refresh_interval":"-1"}}
Disable Replicas
同样,在首次加载大量数据时,我们可以暂时禁用 replica 以提升摄入速度。需要注意的是,这样做可能会带来丢失数据的风险,因此,在数据加载结束后,我们需要再次启用 replica。
PUT /my_index/_settings{"index": {"number_of_replicas":0}}
增加 indexing 线程
处理 knn 的线程由 knn.algo_param.index_thread_qty 指定,默认为 1。如果你的设备有足够的 CPU 资源,可以尝试调高这个参数,会加快 k-NN 索引的构建速度。但是,这可能会增加 CPU 的压力,因此,建议先按节点 vcore 的一半进行配置,并观察 cpu 负载情况。
PUT /_cluster/settings{"transient": {"knn.algo_param.index_thread_qty":8// c6g.4x的vcore为16, 给到 knn 一半}}
左滑查看更多
增加 knn 内存占比
knn.memory.circuit_breaker.limit 是一个关于内存使用的参数,默认值为 50%。如果需要,我们可以将其改成 70%。以这个默认值为例,如果一台机器有 100GB 的内存,由于程序寻址的限制,一般最多分配 JVM 的堆内存为 32GB,则 k-NN 插件会使用剩余的 68GB 中的一半,即 34GB 作为 k-NN 的索引缓存。如果内存使用超过这个值,k-NN 将会删除最近使用最少的向量。该参数在集群规模不变的情况下,提高 k-NN 的缓存命中率,有助于降低成本并提高检索效率。
PUT /_cluster/settings{"transient": {"knn.memory.circuit_breaker.limit":"70%"}}
结语
亚马逊云科技 本文《基于大语言模型知识问答应用落地实践-知识库构建(上)》对于知识库构建部分展开了初步的讨论,基于实践经验对于知识库构建中的一些文档拆分方法,向量模型选择,向量数据库调优等一些主要步骤分享了一些心得,但相对来说比较抽象,具体实践细节请关注下篇。
另外,本文提到的代码细节可以参考配套资料:
代码库 aws-samples/private-llm-qa-bot
https://github.com/aws-samples/private-llm-qa-bot
Workshop <基于Amazon Open Search+大语言模型的智能问答系统>(中英文版本)
https://catalog.us-east-1.prod.workshops.aws/workshops/158a2497-7cbe-4ba4-8bee-2307cb01c08a/



